

Tray Position - Y Axis: The robot demonstrates precise tray manipulation across different Y-axis positions, adapting to left, middle, and right placements.
Tray Position - X Axis: The robot demonstrates adaptive manipulation across various X-axis positions, from 20cm inside the table to 15cm beyond the edge.
Cylinder Position: The robot precisely manipulates cylinders at varied positions, demonstrating adaptive positioning and control.
Robot Position - Y Axis: The robot performs manipulation tasks from different Y-axis positions, demonstrating adaptability to left, middle, and right positions.
Robot Position - X Axis: The robot demonstrates consistent manipulation performance across different X-axis distances, from near to far positions relative to the table.
Table Height: The robot demonstrates remarkable adaptability across various table heights, from 26.5 inches to 31.8 inches, showcasing robust manipulation capabilities.
Lighting Conditions: The robot maintains consistent manipulation performance across different lighting conditions, from bright to dark and flashing environments.
Table Cloth Color: The robot successfully adapts to various table cloth colors, from gray and green to bright colors like yellow, purple, cyan, blue, orange, and red.
Table Type: The robot demonstrates versatility across different table types, showcasing consistent manipulation performance regardless of table material and design.
Object Variety: The robot shows strong adaptability across objects of varying shapes, sizes, and materials.
May 30, 2025: The task is to reach the green/red box based on the visual input. Red box to close fingers, and green box to open fingers.
Failure Cases: While the robot demonstrates robust performance, occasional failures occur including unreliable deployment, hand getting stuck, accidental drops, and challenges with out-of-distribution objects.
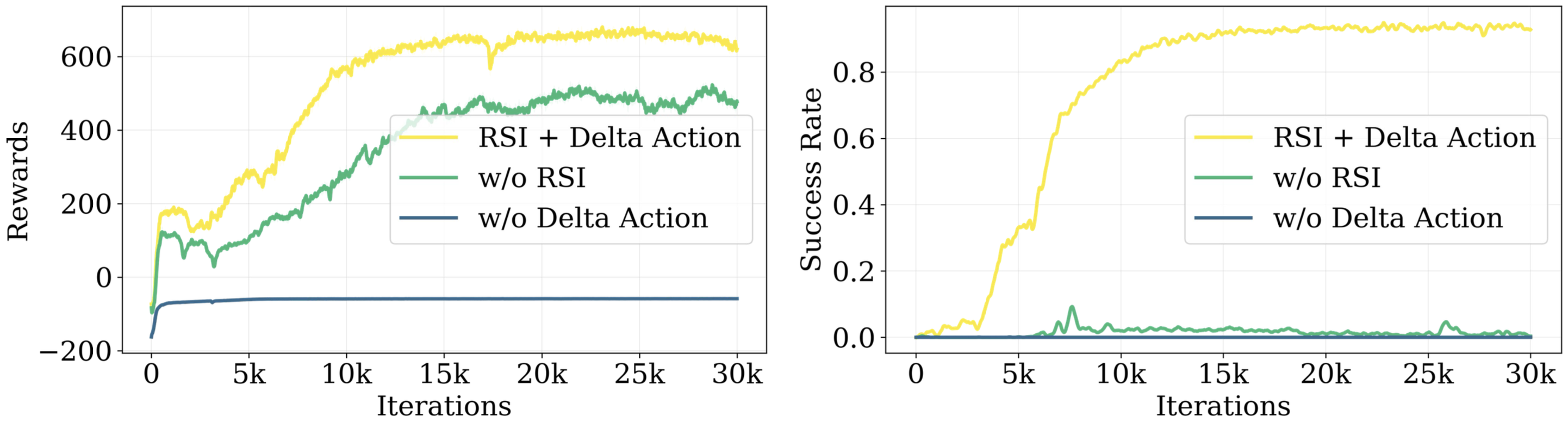
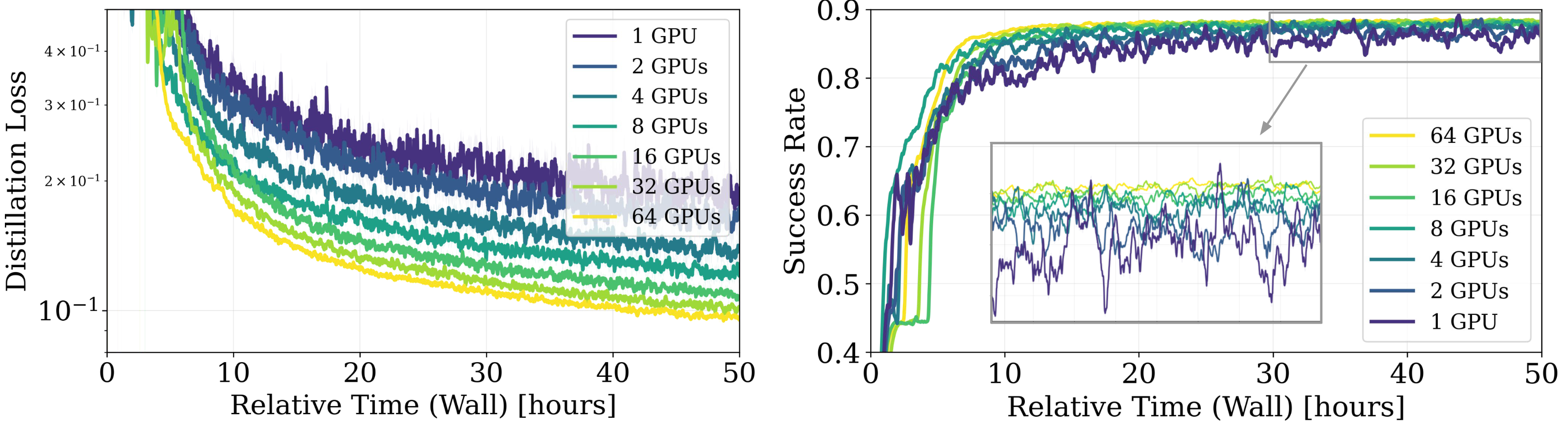
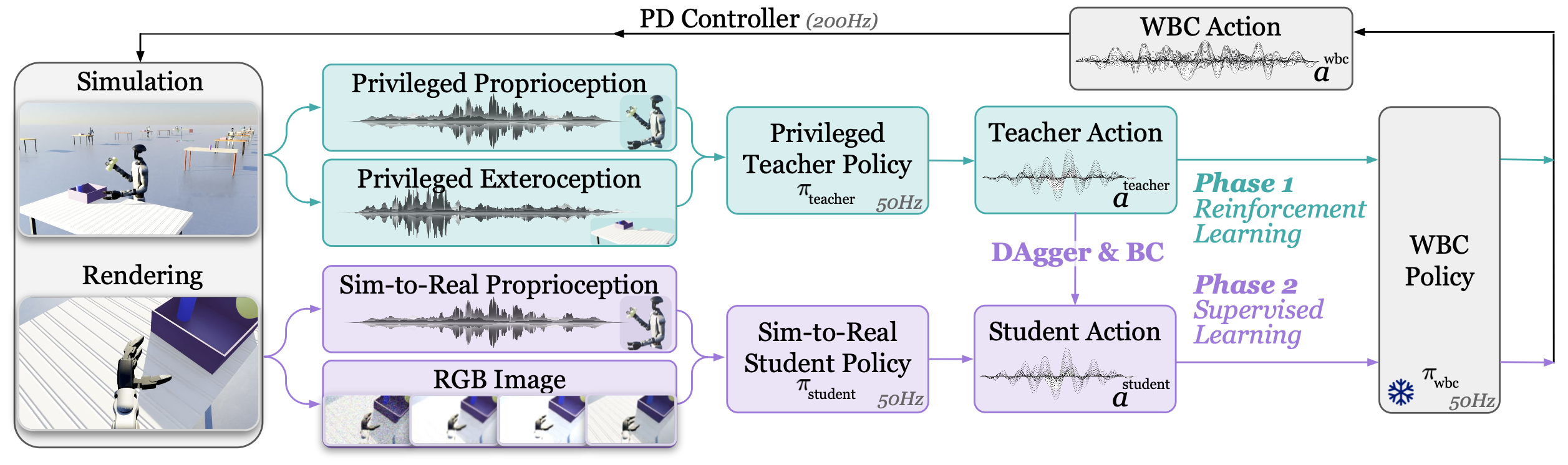
A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays—with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
There are three steps in the VIRAL framework:

@article{he2025viral,
title={VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation},
author={He, Tairan and Wang, Zi and Xue, Haoru and Ben, Qingwei and Luo, Zhengyi and Xiao, Wenli and Yuan, Ye and Da, Xingye and Castañeda, Fernando and Sastry, Shankar and Liu, Changliu and Shi, Guanya and Fan, Linxi and Zhu, Yuke},
journal={arXiv preprint arXiv:2511.15200},
year={2025}
}
